Dspark: Confidence-Scheduled Speculative Decoding con Semi-Autoregressive Generation
DeepSeek è un piccolo laboratorio cinese con risorse limitate: ha un team circa 20 volte più piccolo rispetto a OpenAI e, a causa delle restrizioni sulle esportazioni, non ha accesso alle GPU Nvidia più avanzate.
Proprio per questo non può puntare solo su modelli sempre più grandi o su una potenza di calcolo illimitata. Deve trovare soluzioni più intelligenti.
Ed è qui che emerge la parte interessante: DeepSeek si sta concentrando sull’efficienza, cioè su come far lavorare meglio i modelli già esistenti.
Con l’ultimo paper, dedicato a DSpark, il team presenta un sistema che accelera la generazione dei modelli fino all’85%, senza compromettere la qualità dell’output.
Ma per capire perché è importante, bisogna partire da come funzionano oggi i modelli linguistici.
Come generano i modelli: un token alla volta
Quando usiamo ChatGPT, Claude o DeepSeek, spesso abbiamo l’impressione che il modello “stia pensando”. In realtà, nella fase di risposta succede qualcosa di molto più meccanico: il modello genera testo un token alla volta.
- Prima sceglie il prossimo token.
- Poi guarda tutto quello che ha scritto fin lì.
- Poi sceglie il token successivo.
- E così via.
Questo è uno dei motivi per cui le risposte lunghe richiedono tempo: il modello non genera direttamente tutto il paragrafo in un colpo solo. Deve costruirlo passo dopo passo.
Speculative decoding: il capo e lo stagista
Da tempo esiste una tecnica per accelerare questo processo: speculative decoding.
L’idea è semplice.
Immagina che il modello grande sia un capo molto bravo, ma lento. Ha sempre l’ultima parola, quindi la qualità resta alta, però scrive una parola alla volta.
Per velocizzare il lavoro, gli affianchi uno stagista molto più rapido. Lo stagista prova a scrivere in anticipo qualche parola. Il capo non deve più inventare tutto da zero ma controlla la bozza.
Se la bozza è giusta, accetta più parole insieme. Se trova un errore, scarta da quel punto in poi e riparte.
Il vantaggio è che il modello grande continua ad avere l’ultima decisione, quindi la qualità dell’output non viene sacrificata. Ma se lo stagista indovina spesso, la generazione diventa molto più veloce.
Il problema: draft accurati o veloci, mai entrambi
Il problema è che questi “stagisti” hanno due difetti opposti.
Alcuni sono accurati, ma lenti, perché generano anche loro un token alla volta. Altri sono velocissimi, perché provano a generare più token in parallelo, ma diventano meno affidabili man mano che la bozza si allunga.
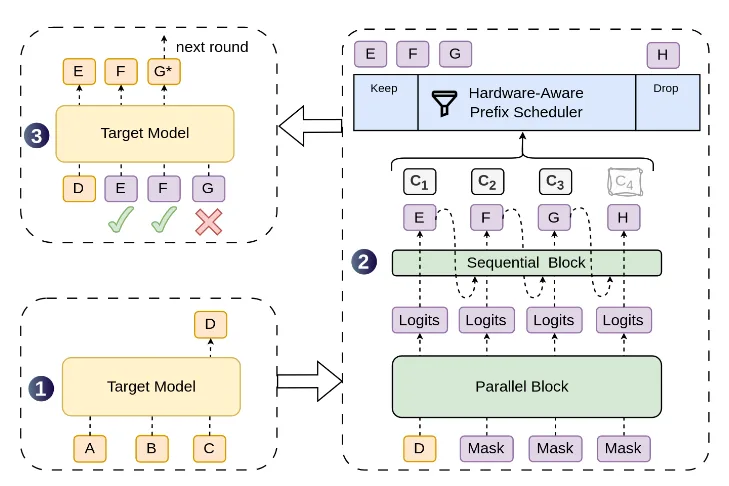
La soluzione di DSpark: Markov head e confidence head
DeepSeek, con DSpark, prova a risolvere proprio questo problema.
La soluzione è elegante e usa un drafter veloce, ma aggiunge due piccoli meccanismi di controllo.
Il primo è un Markov head: una componente leggera che guarda il token appena generato e aiuta a scegliere meglio quello successivo. Non ricostruisce tutta la storia del testo, ma dà al sistema un minimo di continuità locale.
È come dire che se hai appena scritto “a”, probabilmente dopo verrà “volte”, non una parola casuale "gatto".
Il secondo è una confidence head: per ogni token proposto, il sistema stima quanto è sicuro che il modello grande lo accetterà.
Se la confidenza è alta, continua a generare una bozza più lunga. Se la confidenza cala, si ferma prima di sprecare calcolo su parole che verrebbero probabilmente scartate.
Accelerare solo quando conviene
Questa è la parte più interessante: DSpark non prova sempre ad andare alla massima velocità. Decide dinamicamente quando ha senso accelerare e quando conviene essere più prudente.
Su compiti più deterministici, come codice o matematica, può permettersi bozze più lunghe. Su compiti più aperti, come scrittura creativa, tende a fermarsi prima.
In più, il sistema tiene conto anche del carico hardware: se ci sono poche richieste può spingere di più; se il server è sotto pressione, accorcia le bozze per non saturare la GPU.
Il risultato è un sistema che non accelera solo la risposta del singolo utente, ma migliora l’efficienza complessiva del serving.
Perché conta: non solo modelli più grandi
Ed è questo il punto più importante del paper: il progresso negli LLM non passa solo da modelli più grandi.
Passa anche da modi più intelligenti di farli girare.
DSpark mostra una direzione molto concreta: più velocità, meno spreco di compute, migliore utilizzo dell’hardware e nessun bisogno di compromettere la qualità del modello principale.
In un mondo in cui gli agenti fanno task sempre più lunghi, questa non è solo un’ottimizzazione tecnica.
È una parte fondamentale dell’esperienza utente.